
TL;DR
DocETL is an open source system to easily build LLM-powered data processing pipelines. It offers declarative operators that are amenable to powerful optimization, improving accuracy in large-scale, complex document analysis tasks.
- See our demo: https://www.docetl.com/
- GitHub repo: https://github.com/ucbepic/docetl
- Discord community: https://discord.com/invite/fHp7B2X3xx
- Documentation: https://ucbepic.github.io/docetl/
Many researchers and analysts face challenges when processing complex, unstructured documents at scale using Large Language Models (LLMs). The complexity stems from two main factors: first, the logic and iteration required to process collections of texts or documents is intricate and often domain-specific. Second, optimizing these processes for accuracy and efficiency typically requires manual, time-consuming effort.
As part of the Police Records Access Project, our journalism collaborators’ need to analyze heterogeneous police records for officer misconduct patterns (e.g., excessive use-of-force) exemplifies these challenges. Data processing frameworks need to be low-level enough to be easily programmable and adaptable to specific use-cases, yet declarative enough to enable automatic optimization—similar to the benefits database systems provide. This led us to develop DocETL, a system that allows users to express complex document processing pipelines at a higher level of abstraction. DocETL frees analysts from managing complex, low-level details (e.g., manual document chunking, output validation, error recovery), allowing focus on analytical goals.
We illustrate DocETL’s capabilities using a similar (albeit smaller-scale) challenge: analyzing themes in US presidential debates dating back to 1960. This example demonstrates how DocETL can be applied to a range of document analysis tasks, from investigative journalism to historical research, providing a powerful tool for anyone working with large collections of unstructured text data.
Challenges of Complex Document Processing
To introduce the challenges of processing textual documents, let us identify the salient topics from historical presidential debate transcripts and provide representative extracts for each topic. Trying to use LLMs for this task immediately encounters the following challenges:
- Scale: The combined debate transcripts span 738,094 words, far exceeding the context limits of most LLMs.
- Complexity: The task requires multi-step reasoning—identifying themes, tracking their evolution over time, and summarizing viewpoints across multiple debates.
- Accuracy: While LLMs like Gemini-1.5-Pro-002 (released September 24, 2024) can support prompts of 2 million tokens, simply feeding the entire dataset into an LLM in a single prompt leads to incomplete results. For example, when given the entire dataset at once, Gemini-1.5-Pro-002 extracts some themes from several debates, but only reports on the evolution of five themes.
To create a correct and reliable pipeline, there are many potential ways to approach this task, each with its own trade-offs. A single LLM call on the entire dataset is prone to incompleteness. We could ask an LLM to process groups of individual transcripts, but this risks losing global context, and it’s unclear how many transcripts can be processed at once. The challenge lies not just in crafting a pipeline, but in the time-consuming process of optimizing it for accuracy. You might spend days meticulously tuning a pipeline—breaking down your data and task into a carefully-orchestrated swarm of LLM calls—only to find the results disappointing when run on the full dataset. Worse, the rigid structure you’ve built often resists the major refactoring needed to address newly discovered issues.
What’s needed is a more flexible, iterative approach. We need a system that can automatically explore and evaluate different pipeline configurations, decomposing complex operations into sequences of simpler, more accurate ones. This system should focus on tuning optimization decisions, allowing for rapid iteration on high-level goals and analytical objectives without requiring a complete pipeline rebuild..
Introducing DocETL

DocETL is our declarative system for LLM-powered data processing pipelines. DocETL introduces a rich set of document processing operators that are specifically designed for complex text analysis tasks, including splitting large documents, context-aware processing, entity resolution, and iterative refinement of outputs. Users can define pipelines of these operators and their corresponding LLM prompts and validations in YAML (low-code) or Python, and DocETL will optimize them automatically.
Analyzing documents requires reasoning about the goals and document contents, and traditional rule-based optimizations do not work here. Thus, we pioneer an agent-based paradigm for optimizing complex document processing. Here’s how it works:
- User-Defined Pipelines: Users write a pipeline of semantic operations using DocETL’s YAML-based DSL.
- Automated Pipeline Rewriting: DocETL employs LLMs to enhance pipeline accuracy through two mechanisms: query rewriting and quality assessment. Agents implement our predefined rules for semantic task decomposition–that is, they decompose complex operations into simpler, less error-prone ones–resulting in a number of candidate pipelines. Agents also generate task-specific validation criteria and evaluate sample outputs (a la “LLM-as-a-judge”) to compare candidate pipeline configurations.
- Transparent Results: Once the optimization process is complete, DocETL presents the user with the rewritten, optimized pipeline. Users can inspect how the system transformed their initial plan into a more effective one, and then run the optimized pipeline.
Example: US Presidential Debate Analysis Pipeline
Let’s examine how DocETL tackles the presidential debate analysis task:
User-Defined Pipeline
Initially, the user defines a simple map-reduce pipeline in YAML:
- Map: Extract a list of themes and associated viewpoints from each debate transcript.
- Unnest: Flatten the theme structure for easier processing.
- Reduce: Summarize viewpoints per theme across all transcripts.
However, this pipeline faces challenges. First, the map operation identifies 339 distinct themes, many of which are similar (e.g., “social security and medicare” and “medicare and social security”). Second, the reduce operation struggles to consolidate viewpoints for these similar themes effectively; there may be many viewpoints in the input that are not reflected in the output.
DocETL Optimization
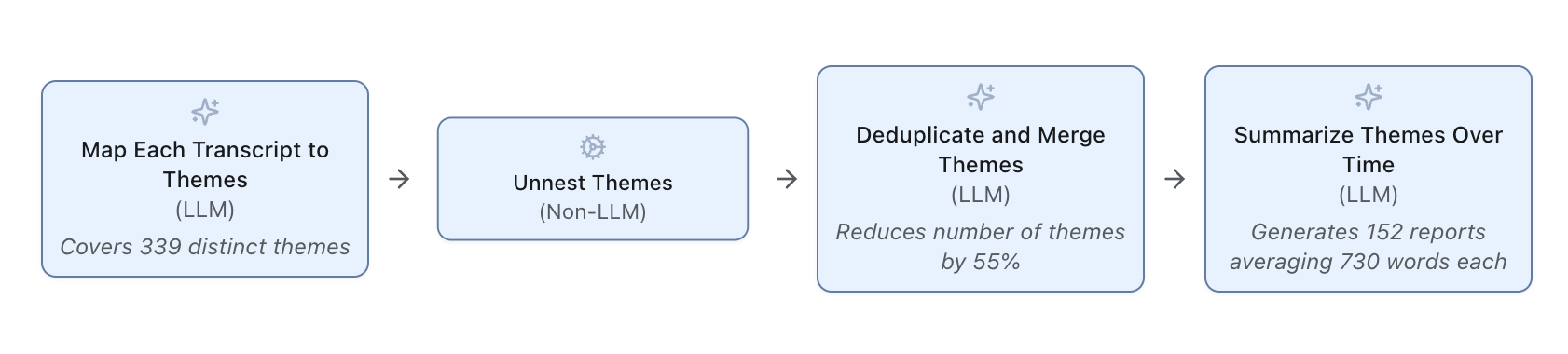
When the user runs docetl build pipeline.yaml, DocETL’s optimizer rewrites the pipeline for improved accuracy. The changes include:
- Theme Canonicalization: A new “resolve” operation is added to canonicalize similar themes, reducing the number of themes by 55%.
- Iterative Refinement: The “reduce” operation is rewritten into a loop of map + reduce operations, allowing for iterative refinement of summaries based on validation (i.e., LLM-as-a-judge) feedback.
The initial optimization process explored various configurations before settling on this efficient pipeline, which costs $0.86 to optimize and $0.29 to run on all debate transcripts. Overall, DocETL’s pipeline generates 152 reports averaging 730 words each, summarizing the evolution of viewpoints for each theme—a significant improvement over the 5-report baseline from Gemini 1.5 Pro 002!
A big advantage of DocETL’s approach is its efficiency in handling human-driven iterations, thanks to caching. For example, if a user wants to tune the summarizer prompt after seeing initial results, DocETL only reruns the necessary parts of the pipeline. A full pipeline iteration might cost $0.29, but a single-operation update may cost only a few cents.
Operators and Rewrite Rules
As we saw earlier, the user can specify their pipeline some operators, and we rewrote it using additional ones. Turns out DocETL provides a comprehensive set of operators for complex document processing tasks. While the full list is available at https://ucbepic.github.io/docetl/, two new operators are specifically designed for long document processing:
- Split: Divides long documents into manageable chunks, critical for texts exceeding LLM token limits or when LLM performance degrades with increasing input size.
- Gather: Augments each chunk with relevant context from other parts of the document, e.g., any metadata or prior content, so the LLM can accurately process the chunk at hand.
To optimize document processing pipelines for accuracy, DocETL employs 13 LLM-specific rewrite rules spanning three categories:
- Data Decomposition: These rules focus on breaking down large documents or complex data structures into more manageable pieces.
- Projection Synthesis: These rules introduce intermediate steps to refine or preprocess data without necessarily resorting to chunking.
- LLM-Centric Improvements: These rules leverage unique properties of LLMs to enhance output quality. For example, LLMs are nondeterministic and inconsistent, necessitating entity resolution operations. Or, LLMs benefit from self-correction and iterative improvement, given feedback.
These rules enable DocETL to explore various pipeline configurations, decomposing complex operations into sequences of simpler, more accurate ones. For example, a single complex map operation might be rewritten into a series of operations: splitting the document, gathering context for each chunk, applying a modified map to each context-augmented chunk, and then reducing the results. This approach addresses challenges such as processing large documents that exceed LLM context limits, maintaining coherence across document sections, and leveraging LLMs’ ability to refine their own outputs. Full descriptions of these rewrite rules and their applications will be available in our upcoming paper–stay tuned!
Towards a Robust No-Code, Interactive, and Accuracy-Optimized System
Our vision is to develop a fully no-code and interactive system for accurate, intelligent unstructured data processing. This presents exciting research challenges:
- How can we translate natural language task descriptions into optimized LLM pipelines? This involves not only understanding the user’s intent but also automatically identifying the most effective starting sequence of operations to achieve the desired outcome.
- What’s the best way to incorporate user feedback for iterative refinement of pipelines? Users often don’t know what makes for good “acceptance criteria” until they see the initial LLM output. We need to design intuitive interfaces that allow users to provide feedback on intermediate results and DocETL-synthesized validator prompts, and guide the optimization process.
- How do we make the optimization process fast, transparent and debuggable? End-to-end optimization times for super-complex pipelines (e.g., the police misconduct identification pipeline) can take over 30 minutes. Ideally, we can provide users with insights into why certain decisions were made (e.g., how we rewrote an operation) and how to troubleshoot issues when they arise, interactively.
- How can we improve the reliability of our LLM agents in generating high-quality rewrites? This involves developing techniques to reduce output variability and improve the reliability of generated pipeline optimizations without extensive resampling.
DocETL is an open-source project aimed at advancing LLM-powered unstructured data analysis. To explore its capabilities, visit https://www.docetl.com/ and try our presidential debate analysis demo. If you’re interested in contributing to the project or staying updated on its development, please star our GitHub repository. For any technical help or discussions on unstructured data processing challenges and LLM output quality at scale, join our Discord community. We look forward to your feedback to help shape the future of AI-assisted document analysis tools!