
Many real-world documents (think PDFs and Word files) often contain structured data embedded within, such as tables or key-value pairs. A particularly common class of documents are those that are programmatically generated by filling fields following a visual template—we call these templatized documents—think tax forms, invoices, financial reports, pay stubs, certification records, expense reports, and purchase orders. These documents contain a rich treasure trove of information, all locked away in inaccessible formats. What if we could liberate structured data from these PDF and Word prisons?
Unfortunately, doing so is challenging: first, the documents vary in format, often employing a visual template with a heterogeneous, nested structure, including tables and key-value pairs. Second, the scale of such documents trips us up because they can be easily generated at scale programmatically following the visual template.
But surely there’s a tool for this! Unfortunately, state-of-the-art data extraction APIs (e.g., AWS Textract or Azure Document Intelligence) or text- or vision-based Large Language Models (LLMs) don’t quite work: they achieve only 25%–65% precision and recall on a benchmark of 34 real-world datasets. And they definitely don’t work at scale, incurring high cost and latency because they operate page-by-page. For example, GPT-4 Vision takes 30+ hours and $50+ to extract data from 2000+ pages.
So, we ask the question: can we first infer the underlying template in such documents, and then extract data, rather than directly extracting from documents? We use this insight to develop TWIX, a data extraction tool that extracts structured data from a templatized document collection by reconstructing its template. TWIX infers the underlying template, which encodes how the structured data is organized in documents, and then further extracts data based on the template at no-cost, efficiently, and accurately.
TWIX outperforms 6 state-of-the-art data extraction tools by over 25% in precision and recall, and is 520× faster and 3786× cheaper than the most competitive baseline, GPT-4 Vision. Instead of relying on LLMs to do the extraction from complex documents, TWIX uses careful reasoning about the repeated nature of the visual template—coupled with careful invocations of LLMs to help impart semantic information—to provide a solution that dominates others across all aspects: cost, accuracy, and speed.
Challenges in Structured Data Extraction from Documents
Templatized documents—those generated from structured data using a consistent visual template—are everywhere. Think: invoices, pay stubs, police reports, tax forms. They’re visually repetitive, but extracting structured data from them remains a challenge for existing tools. Why?
- Heterogeneity: These documents blend tables, key-value blocks, and metadata.
- Visual Complexity: Extracting data means understanding not just text but layout—what’s aligned, nested, and repeated.
- Cost & Latency: Data extraction page by page using LLMs or pretrained extraction APIs is painfully slow and expensive.
Our Insight
Instead of treating data extraction in every page as a fresh problem, TWIX reverses the generation process: it infers the underlying template first, then uses that template to extract structured data efficiently from any document that follows it.
Illustrative Example
We illustrate TWIX’s capabilities via a document collection of police complaint records, provided by our collaborators. Two such records are shown below, and the structured data of the first record is shown left to it. In this document collection, every single record has a consistent visual template—they all consist of a table, a list of key-value pairs, followed by two additional tables. If we can infer such a template, along with the corresponding fields (e.g., table columns or keywords in key-value pairs), we can then use it to decompose a long and complex document that follows this template into a set of data blocks with simple structures, such as tables or key-value pairs.
Introducing TWIX
Overview
TWIX follows a four-stage pipeline:

- Phrase Extraction: Use Optical Character Recognition (OCR) tool to extract text phrases and bounding boxes.
- Field Inference: Cluster phrases by their visual location patterns to identify field candidates.
- Template Inference: Infer the document’s structure by inferring row labels with visual constraints based on inferred fields.
- Data Extraction: Apply the inferred template to extract structured data efficiently and accurately at scale.
Key Techniques
1. Field Inference via Location Patterns and LLMs
Our key insight is that fields tend to appear in similar locations across records, while the values for the same field can be different across records.
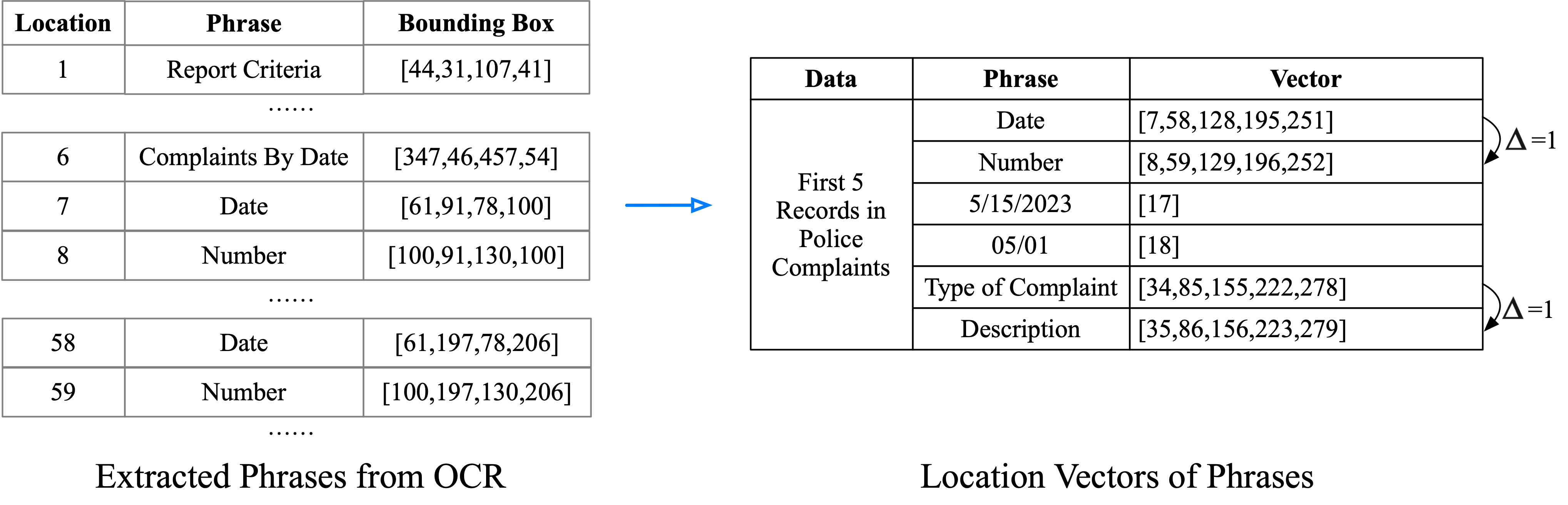
Consider the phrases extracted by an OCR tool (left figure below), where the location is the order of extraction (e.g., Report Criteria and Date in Record 1 are the 1st and 7th phrases). If we then assemble every location where a given phrase appears into a vector (right figure below), for fields like Date and Number, the difference in their location vectors is constant, since Number is always the next extracted phrase to Date in every record. Among all phrases in the document, typically only a small subset (corresponding to fields) exhibits the consistent location pattern as described above with constant differences. On the other hand, most values (e.g., 05-01) appear randomly across records and their location vectors are often not consistent.
TWIX uses a clustering approach to group phrases with consistent location patterns. When visual cues prove insufficient (e.g., the value for a field is constant across records), TWIX uses the semantic knowledge of LLMs. Instead of relying on LLMs to handle complex tasks, such as recognizing intricate visual layouts, we restrict their role to simple questions, like “Is this phrase a field or a value?”, making less-advanced but much cheaper LLMs capable of answering questions well.
2. Template Inference via Integer Linear Program
TWIX models the template as a tree, where each node corresponds to a set of data blocks (tables or key-value pairs), and each edge denotes the nested relationship among data blocks. To infer structure, TWIX infers the labels of each row as a potential Key, Value, Key-Value, or Metadata row based on inferred fields, then solves a constrained optimization problem using Integer Linear Programming (ILP) to infer the template structure.

Why TWIX Wins
Once the template is inferred in a small document portion, a complex document can be decomposed into data blocks with simple structures, either tables or key-values. TWIX can then process the rest of the documents without any LLM calls. This means TWIX:
- Has zero cost to perform data extraction after template inference.
- Scales to large datasets.
- Has high accuracy due to template-based document decomposition.
- Maintains data relationships, preserving table and key-value structures automatically.
Datasets
With help from our collaborators and other sources, we collected two benchmarks:
- Q-Benchmark: 34 real-world datasets with available labeled data, focusing on evaluating the precision and recall of compared tools.
- S-Benchmark: 30 large datasets, around 2,133 documents and over two million tokens per dataset, focusing on evaluating scalability (latency and cost).
Baselines
We compare TWIX with six baselines:
- Amazon Textract and Azure AI Document Intelligence (AzureDI): extract tables and key-value pairs from PDFs.
- vLLM-S and vLLM-C (vision-based LLMs powered by GPT-4 Vision).
- Evaporate-Direct (Eva-D) and Evaporate-Code (Eva-C) (text-based LLM systems).
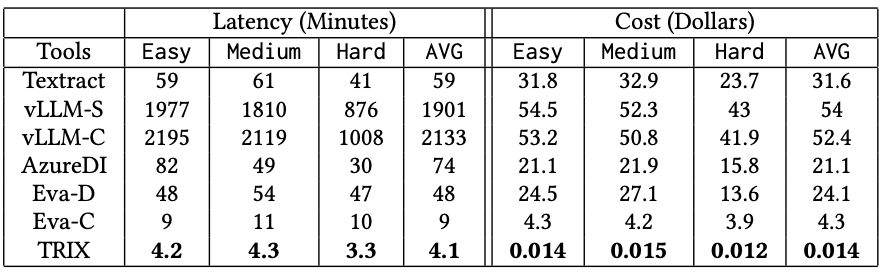
Results show TWIX outperforms the baselines by over 25% in precision and recall in Q-Benchmark, and is 520× faster and 3786× cheaper than the most competitive baseline, GPT-4 Vision, in S-Benchmark.
This demonstrates that template inference is crucial for data extraction from templatized documents, by reducing document complexity and enabling scalable and accurate extraction.

Interactive User Interface
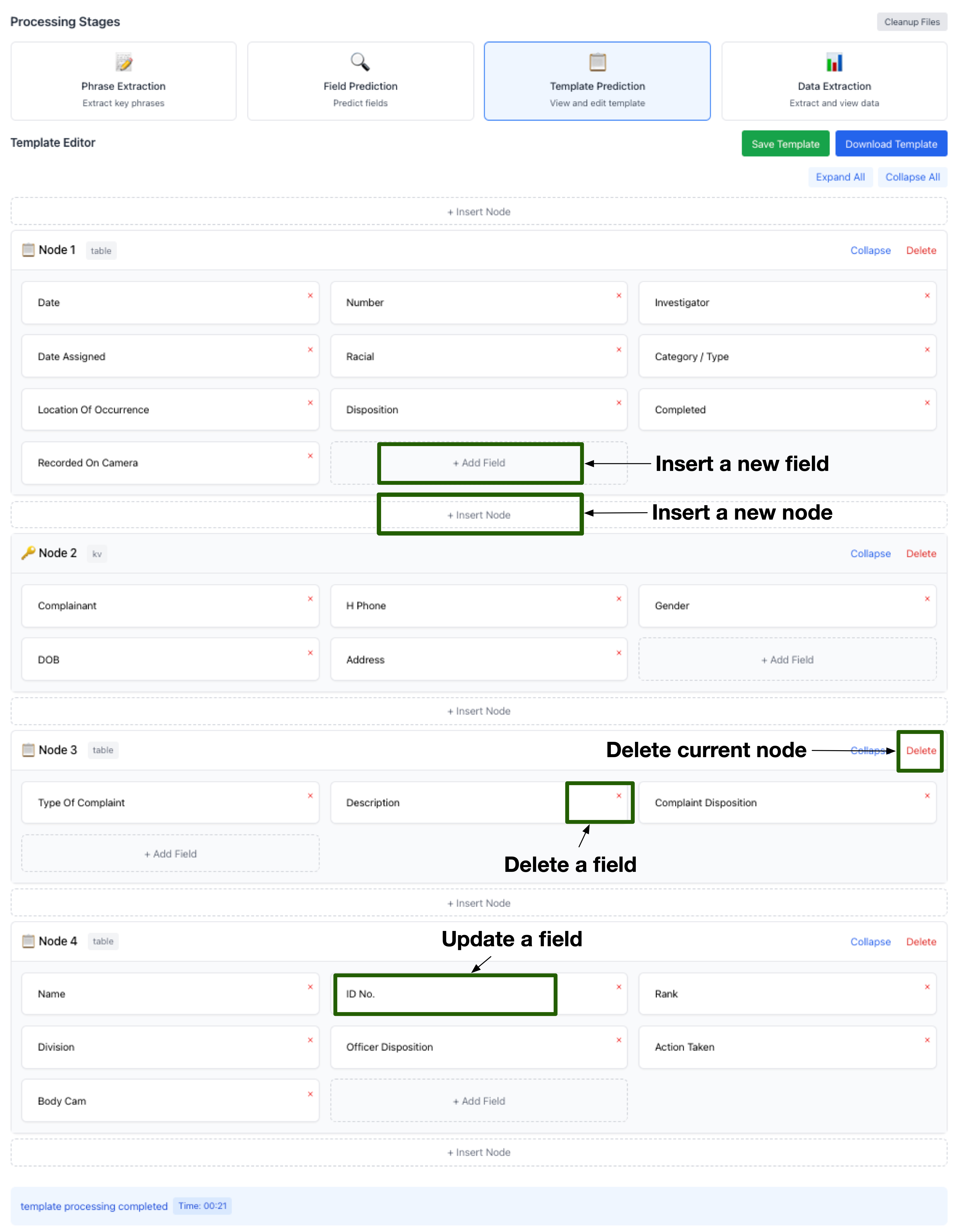
While TWIX handily beats the baselines, template inference is never perfect. This led us to build a user interface to incorporate humans in the loop to further enhance the accuracy of data extraction.
The UI allows users to:
- Examine and edit the inferred template.
- Update/add/delete inferred fields.
- Adjust the hierarchical structure by updating/adding/deleting nodes and edges.
You can explore more here:
https://github.com/ucbepic/TWIX.git
Learn More and Try It Out
If you’re interested in learning more about TWIX’s approach, check out our research preprint.
TWIX is an open-source project. The codebase includes:
- Detailed instructions for using TWIX as a Python library.
- A user interface mode for non-programmers.
- Sample documents to get started.
Try it out here: