
LLMs are increasingly being used to process large-scale text datasets (or equivalently, text columns in relational datasets). They could, for example, filter text records based on a natural language condition, extract a desired attribute from each record, or classify them based on some property. These tasks essentially follow the same recipe: apply an LLM with a fixed prompt to every record in the dataset, one by one. To get high accuracy for such tasks, users want to apply top-of-the-line LLMs, but this quickly gets expensive—the more so the larger the dataset and the longer the texts are. We introduce the BARGAIN library, which reduces cost by using a cheaper LLM to process the records whenever possible, but provides statistically guarantees similar accuracy as top-of-the-line LLMs. So you get low cost and high accuracy when processing data with LLMs!
How Does it Work
To process a data (i.e., text) record with an LLM given a prompt, BARGAIN first runs the cheap model on the data record. Based on the model’s output log-probabilities it decides whether to trust the cheap model or not. If it decides the cheap model’s output is inaccurate, it then runs the more expensive model.
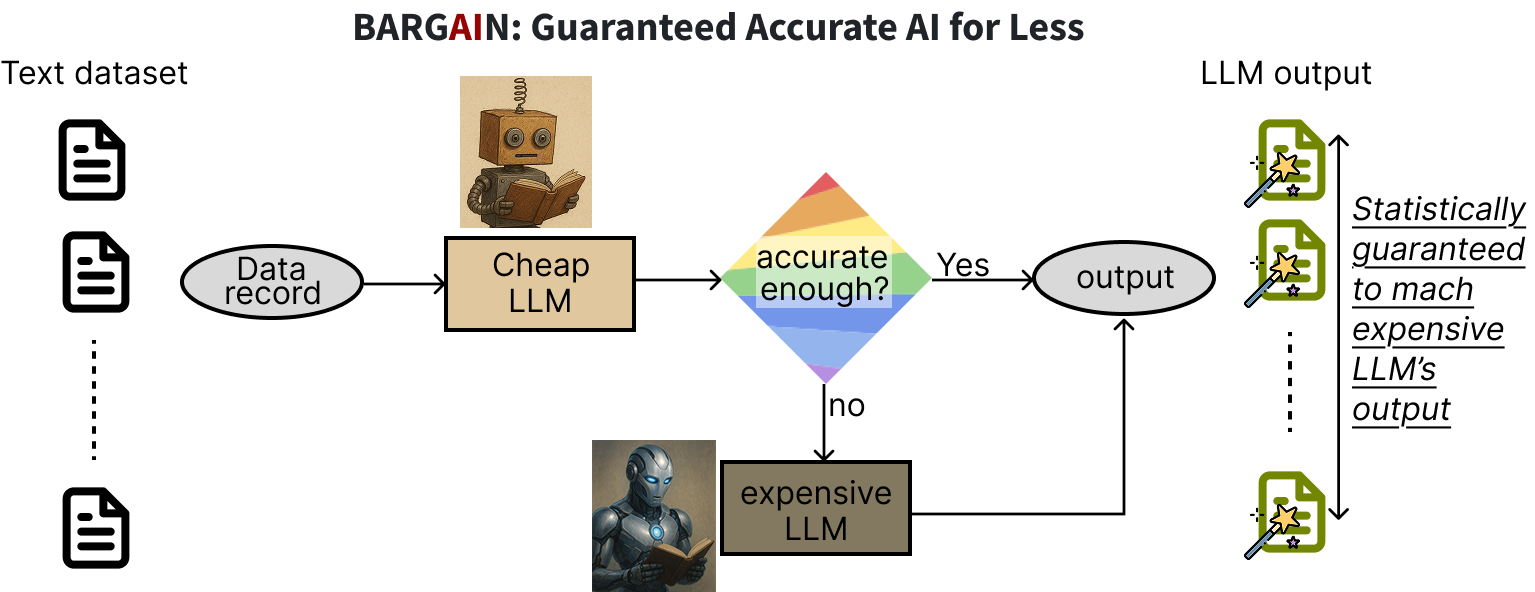
To decide whether to trust the cheap model, BARGAIN uses a threshold on its log-probabilities: if the cheap model’s output log-probability is more than the threshold, BARGAIN uses the cheap model’s output but otherwise uses the more expensive model. Easy peasy!
The magic all comes down to determining the threshold, which happens in a preprocessing step. The threshold is set to a value that provides the following theoretical guarantees on output accuracy: given an accuracy target T, BARGAIN guarantees the output matches the expensive model’s output at least on T% of the data records, but uses the cheap model on as many records as possible. This guarantee is achieved through sampling and labeling a few records in a calibration step to estimate a suitable threshold on log-probabilities. BARGAIN also supports providing theoretical guarantees on recall and precision metrics for filtering tasks, in addition to accuracy. BARGAIN makes use of sophisticated statistical machinery from recent work in statistics, making it possible to provide tight guarantees with few samples.
Why BARGAIN?
There are many systems that claim to reduce cost while providing good accuracy. Most don’t provide any guarantees at all on output accuracy (e.g., FrugalGPT) and may cut cost at the expense of accuracy. BARGAIN reduces costs while providing theoretical guarantees on output accuracy.
Until BARGAIN, the state-of-the-art approach that provided guarantees was SUPG, which unfortunately provides weaker guarantees and worse utility: it uses the expensive LLM much more than needed to provide a weaker accuracy guarantee than BARGAIN. BARGAIN provides these benefits through an improved sampling process (BARGAIN performs adaptive sampling) and better estimation of LLM accuracy (BARGAIN uses recent statistical tools for estimation).
We compared SUPG with BARGAIN across 8 different real-world datasets in the figure below, comparing the fraction of expensive LLM calls avoided (to measure cost savings), averaged across the datasets. BARGAIN reduces cost significantly more than SUPG. The figure also shows a naive method that provides the same theoretical guarantees as BARGAIN with a naive sampling and estimation process (using uniform sampling and Hoeffding’s inequality for estimation). The results show that BARGAIN’s innovations in sampling and estimation are necessary to achieve high utility.
Overall, BARGAIN reduces use of expensive models by more than 86% compared with state-of-the-art while guaranteeing 90% accuracy.

Use BARGAIN and Read More
Try out BARGAIN here and read more about it in our SIGMOD’26 paper. We’d love to hear any feedback! Reach out at: zeighami@berkeley.edu or file an issue on GitHub!