
TLDR:
- Try DocWrangler at docetl.org/playground
- Star our GitHub repository to follow development
- Join our Discord community for technical discussions and support
- See a video demo of using DocWrangler to analyze common complaints in ICLR 2025 submission reviews
LLM-powered data processing pipelines have a lot of promise, but building them is painful. Even with pipeline libraries like DocETL, getting LLMs to do what you want involves constantly cycling between writing prompts, inspecting results, and refining both your prompts and your goals as you discover what’s actually possible.1 So, we built DocWrangler, an interactive development environment (IDE) that makes this process much easier through instant feedback, visual exploration tools, and AI-powered assistance. DocWrangler is open-source, and a hosted version is available at docetl.org/playground (no sign-up required).
In this blog post, we’ll show you how DocWrangler improves the experience of working with LLM pipelines, whether you’re new to LLM-powered data processing or an experienced practitioner looking to streamline your workflow. We’ll discuss our motivations for building DocWrangler, demonstrate its features through practical examples, and share tips we’ve learned from successful users. Finally, we’ll conclude with what’s next.
Why We Built DocWrangler
LLM-powered data processing enables people to tackle complex tasks on unstructured data. Instead of writing code or training models to extract information from text and summarize this information across document boundaries, or hiring domain experts to make sense of the data, you can express what you want in natural language and let LLMs handle the heavy lifting. For example, imagine analyzing a collection of customer support call transcripts. You might build a pipeline like this:

Our system, DocETL, provides a declarative way to build these pipelines, similar to how SQL lets you express database operations without worrying about execution details.2 Since our release in September 2024, however, we’ve observed that many users struggle to write LLM-powered data processing pipelines effectively. In addition to the stage-specific challenges in the figure above, the challenges run deeper than just “prompt engineering is hard.” Users often start with one goal in mind, only to discover they actually want something different once they see initial results. For example, when analyzing customer support conversations, you might think you want to extract specific issues mentioned. But after seeing the LLM’s outputs, you realize what you really want is to identify patterns in how support agents handle different types of complaints—something you couldn’t articulate until you saw the data processed in different ways.
This kind of iterative refinement isn’t unique to LLMs. For example, early data cleaning systems like Potter’s Wheel and Wrangler (which evolved into Trifacta) recognized that data transformation is inherently exploratory. Users need to see the effects of their changes immediately to understand if they’re moving in the right direction. LLM-powered data processing demands something more; an environment built around rapid iteration between examining data and refining pipelines, tools for exploring and validating LLM outputs at scale, and support for the natural evolution of analytical goals as you discover what’s possible with your data and the LLM (bridging the gulf of envisioning).
Existing development interfaces don’t adequately support this workflow. Traditional IDEs and LLM pipeline builders focus on chaining simple prompts rather than supporting complex data processing operations, and none provide the rich, immediate feedback loop needed to work effectively with LLMs. This is the gap DocWrangler aims to fill.
What is DocWrangler?
DocWrangler is an IDE designed for building and refining LLM-powered data processing pipelines. While the core ideas behind DocWrangler could support any LLM data processing framework, our current implementation is built on top of DocETL. As the primary developers of DocETL and having worked closely with its growing user base, it was natural for us to start there.
The IDE adds an interactive layer that makes it easier to explore your data, experiment with different operations, and refine your pipelines based on what you discover. You can try it out at docetl.org/playground, where we’ve included two example datasets to help you get started (click on Help -> Tutorials):
- US Supreme Court oral arguments from 2024–this will cost $0.11 to run with gpt-4o-mini
- Airline customer support chat logs–this will cost $0.05 to run with gpt-4o-mini
These datasets showcase different types of analysis you might want to perform with LLM-powered pipelines.
Key Features
Building LLM pipelines today involves several challenges: assessing LLM outputs at scale to catch issues like hallucinations or inconsistencies, making targeted improvements without getting lost in prompt engineering trial-and-error, and mastering new concepts like pipeline patterns and templating syntax, and even getting comfortable with the exploratory nature of data analysis. DocWrangler’s features directly address these pain points through rich visualization tools, in-context feedback mechanisms, and intelligent assistance. Let’s look at each in detail:
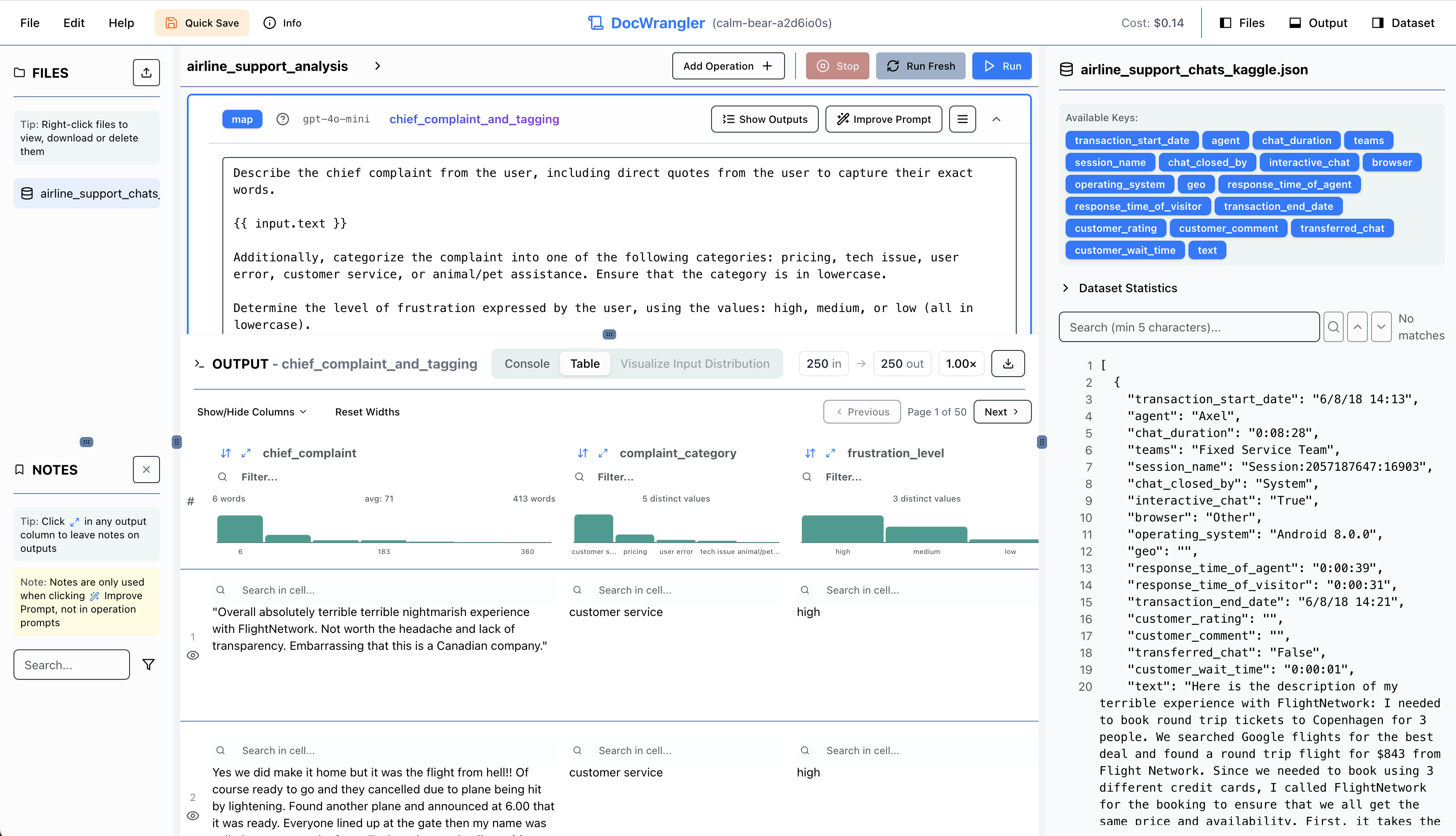
Spreadsheet Interface with Automatic Summary Overlays
DocWrangler combines a notebook-style pipeline editor with a spreadsheet-like output viewer. The editor lets you build your pipeline step by step, while the viewer provides functionality for exploring and validating outputs. In the output viewer, you can resize rows and columns, search within cells, and sort or filter columns–-capabilities that prove invaluable when working with LLM outputs. The search functionality is particularly useful for validating extractions and checking for hallucinations. For example, if you’ve asked the LLM to extract key phrases from documents, you can quickly search the source text to verify these phrases actually appear.
DocWrangler’s output viewer also offers basic automatic visualization capabilities, inspired by Trifacta. Based on the data type of each output field, the system generates appropriate visualizations to help you spot patterns and potential issues; e.g., for text fields, it shows histograms of word or character counts; for lists, it displays distributions of the number of elements; for categorical data, it automatically detects and visualizes the distribution of categories. These visualizations are very useful for sanity checking your pipeline’s behavior at a glance. For instance, if you’re extracting entities from documents, a sudden spike in the length distribution might indicate the LLM is being too verbose or including irrelevant information. Often we see some outputs even have too few words because the LLM “refused” to do the task, and the visualizations help detect these quickly.
In-Situ Fine-Grained Feedback and Intelligent Prompt Refinement
Traditional approaches to prompt engineering fall short for real-world data processing tasks. Many methods rely on labeled examples to optimize prompts, but users rarely have these on hand. So, some systems try to use powerful LLMs like GPT-4 as oracles to generate labeled examples, but this assumes tasks have clear right and wrong answers. In reality, data processing tasks are often flexible—take “extract common complaints from customer feedback.” Should the LLM identify specific issues like “password reset email never arrived” or higher-level categories like “account access problems”? Users often discover their preferred granularity only after seeing some outputs.
Beyond these limitations, traditional prompt engineering forces users to mentally juggle between examining outputs, identifying issues, and figuring out how to fix them through prompt changes. DocWrangler takes a different approach, letting you provide feedback naturally as you inspect outputs. The interface shows one row at a time while maintaining context, with split views available to examine source documents or intermediate outputs side-by-side. You can attach observations directly to specific outputs—like “this summary missed key details” or “categorization is too granular here.”
DocWrangler then analyzes your row-level feedback to suggest targeted prompt improvements, showing clear diffs. You can iterate on these suggestions or branch into different directions, with full version control to track your exploration. This tight feedback loop between inspection and refinement reduces the cognitive load of improving your pipeline.
We’ve been excited to see how quickly users have adopted this feedback loop, even without formal training. The ability to move fluidly between output inspection, feedback, and prompt refinement seems to match how people naturally think about improving their pipelines.
DocWrangler Assistant
LLM-powered data processing involves several new concepts to master, from DocETL’s syntax to effective prompt design patterns. To help users get started, DocWrangler includes a context-aware AI assistant that understands your pipeline and can explain concepts as you need them. The assistant can be used in many ways: e.g., it helps with technical concepts like Jinja templates by explaining them using examples from your own prompts, or it can suggest structural improvements based on common pipeline patterns. While experienced users may not need this help, we’ve found it reduces the time it takes to become productive with LLM pipelines.3 Of course, we should note that this is still an LLM-powered chatbot. It may occasionally hallucinate, for instance. So, think of it as a helpful “companion” in your data processing journey, not an oracle.
Note: If you use our AI features, we log chatbot and prompt engineering queries for our research purposes. We do not plan on open-sourcing the data, but in the case that we do so (later down the line), this data will not be open-sourced without careful anonymization and PII removal, following standard research practices. If you do not want us to log usage data, you can provide your OpenAI API key.
Tips for LLM-Powered Data Processing
Excited to get started with your own dataset and task? Based on what we’ve observed from users on DocWrangler, here are a few “good practices”:
1. Start with Data Inspection
- Upload your data and carefully inspect it in the viewer
- Set your API keys, dataset description, and a manageable sample size (10-20 documents)
2. Start with Open-Ended Data Exploration
- Begin with broad, exploratory operations to understand your data–map operations are very useful tools for data exploration
- Write prompts that encourage exhaustive responses, like “extract information that might be relevant to X and summarize key points.” Essentially, let the LLM include potentially relevant information to help build a mental model of your dataset.
- Keep output schemas simple initially–you can add structure later
- Remember: prompts are Jinja templates (check DocETL docs or ask the AI assistant for syntax help)
3. Iterate One Step at a Time
- Build your pipeline operation by operation
- Examine outputs one example at a time
- Keep providing notes until you stop learning new things about your data/LLM behavior
- Take advantage of the prompt improvement assistant
- Gradually add more structure to your schemas as your understanding improves
4. Handle Complexity
- For very long documents or complex tasks, try the experimental optimize operation functionality, accessible through the operation menu dropdown. This will perform data or task decomposition (or both).
- For resolve operations, always run optimization to make the operation cheaper and faster. Note that the optimizer requires OpenAI API keys.
What’s Next for DocWrangler
While this current version of DocWrangler is already very powerful, there are several more exciting ideas we are thinking about:
- Richer dynamic visualizations specific to each operator type, and the semantic meaning of the operation
- Enhanced validation support, including:
- Direct editing of individual outputs
- Persistence of these direct edits across runs, even when there are prompt changes
- More interactive optimization capabilities
If you’re interested in contributing to any of the above, or another DocWrangler project, please reach out to shreyashankar@berkeley.edu. You do not have to be a Berkeley student to join the group, but please mention it in your email if you are!
DocWrangler is part of our broader mission to make LLM-powered data processing more accessible and effective. Our upcoming DocWrangler research paper will share our design principles, implementation details, and insights from our user studies–stay tuned! In the meantime, you can: try DocWrangler at docetl.org/playground, star our GitHub repository to follow development, and join our Discord community for technical discussions and support. A video demo of using DocWrangler to analyze common complaints in ICLR 2025 submission reviews is available here; to help you get familiar with both the DocWrangler workflow and LLM-powered data processing in general.
We’re excited to see how you’ll use DocWrangler in your own workflows and look forward to your feedback as we continue improving the IDE. Your experiences and suggestions will help shape the future of LLM-powered data processing tools!
Acknowledgments: We’re grateful to Stephen Lee and Mawil Hasan for their collaboration and invaluable help with user studies, and to James Smith and Björn Hartmann for their insightful feedback throughout this project. This public research preview of DocWrangler is made possible by generous credits from Modal Labs and Microsoft.
-
This iterative refinement is necessary because of a fundamental design challenge in complex LLM workflows—what Subramonyam et al. call bridging the “gulf of envisioning” between your goals and effective LLM interactions. ↩
-
LLM-powered data processing is a rapidly growing field, with many research teams and startups developing systems. Some, like DocETL, focus on executing open-ended dataflow operations (e.g., map, reduce), such as Palimpzest from MIT, LOTUS from Stanford, and Sycamore from Aryn. Others target specific tasks, such as LLooM for topic induction and analysis and DiscipLink for aggregating and linking research papers based on user queries. ↩
-
Making this work required solving some interesting technical challenges, particularly around managing context windows (since datasets, pipelines, and sample outputs can easily exceed LLM token limits)—perhaps we’ll write another post about those solutions later, but feel free to ask about them on Discord if you’re curious! ↩